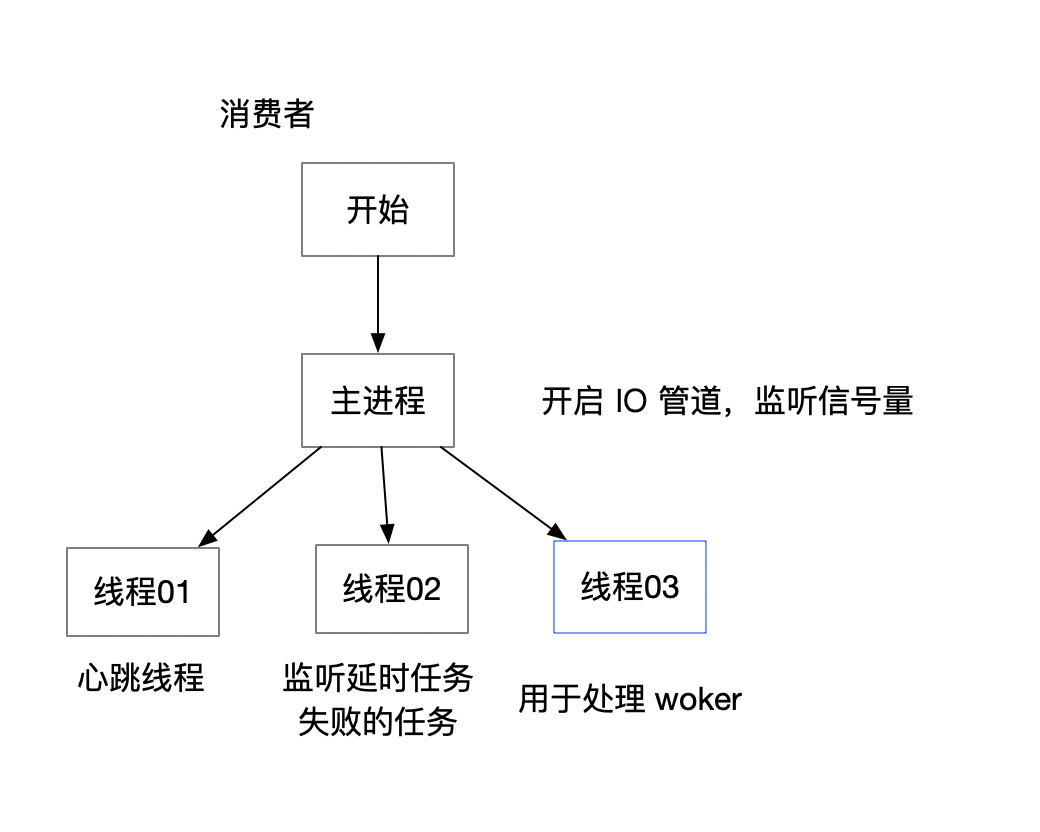
以下内容有删减 # 首先,打开了管道 self_read, self_write = IO.pipe # 注册信号量 sigs.each do |sig| trap sig do self_write.write("#{sig}\n") end end
launcher.run # 主要方法
# 死循环一直读取管道,直到发送了信号量才进行 handle_signal,可参考后面的信号量说明 while (readable_io = IO.select([self_read])) signal = readable_io.first[0].gets.strip handle_signal(signal) end
classEnq defenqueue_jobs(now = Time.now.to_f.to_s, sorted_sets = SETS) # A job's "score" in Redis is the time at which it should be processed. # Just check Redis for the set of jobs with a timestamp before now. Sidekiq.redis do |conn| sorted_sets.each do |sorted_set| # Get the next item in the queue if it's score (time to execute) is <= now. # We need to go through the list one at a time to reduce the risk of something # going wrong between the time jobs are popped from the scheduled queue and when # they are pushed onto a work queue and losing the jobs. while (job = conn.zrangebyscore(sorted_set, "-inf", now, limit: [0, 1]).first)
# Pop item off the queue and add it to the work queue. If the job can't be popped from # the queue, it's because another process already popped it so we can move on to the # next one. if conn.zrem(sorted_set, job) Sidekiq::Client.push(Sidekiq.load_json(job)) Sidekiq.logger.debug { "enqueued #{sorted_set}: #{job}" } end end end end end end
sigs = %w[INT TERM TTIN TSTP] ... sigs.each do |sig| trap sig do self_write.write("#{sig}\n") end rescue ArgumentError puts "Signal #{sig} not supported" end
Sidekiq.configure_client do |config| config.redis = { db:1 } end
Sidekiq.configure_server do |config| config.redis = { db:1 } end
Sidekiq.configure_client do |config| classMyClientHook defcall(worker_class, msg, queue, redis_pool) puts "Before push" result = yield puts "After push" puts result result end end config.client_middleware do |chain| chain.add MyClientHook end end