什么是持久化?
redis 为了提高获取数据的速度,把数据都存储在内存里面。但是快往往是需要付出代价的,每当程序崩溃或者系统意外重启的时候,存储在内存里面的数据就不复存在了,所以需要一种机制来保证数据可以在意外崩溃的时候恢复。
持久化的两种方式
- RDB快照
- AOF(append-only-file)
RDB快照
save 命令
执行 save 命令将会阻塞当前客户端的处理,此时,客户端所进行的工作仅仅只是把内存中的数据存储到 dump.rdb 文件里面去
save命令可以通过 save 60 10000 这种形式来设置 60秒内有10000次写入 就会触发一次 bgsave 命令
bgsave 命令
bgsave 命令与 save 命令的区别在于,bgsave 会 fork 一个新的进程来专门负责数据的备份,而主进程客户端将继续处理读写请求。
存在问题
当数据只有几个 GB 的时候,使用快照来存储自然是没有问题,但是当数据量剧增的时候,比方说当内存数据增加到100个G,bgsave 方式 fork 子进程所耗费的时间也越来越多,从而可能会导致系统性能底下等问题,甚至可能导致 Redis 暂时停顿数秒
如何解决
这种情况下可以考虑关闭自动保存快照的功能,转用手动执行。但是手动执行带来的风险就是可能会丢失数据,如果是对系统要求极为严格的程序,考虑使用 AOF 功能
AOF(append-only-file)
区别于 rdb 的快照存储方式,AOF 存储方式并不是存储内存里面的数据,而是存储写操作的命令。比如说:set message 1,快照的方式会存储 message 1 这条数据,而 aof 的方式会把 set message 1 这条命令记录到 appendfile.aof 这个文件中,为了让体积尽可能小,redis 不会直接明文存储这句命令,而是通过 redis 的通信协议(RESP)格式来进行存储
AOF 工作流程
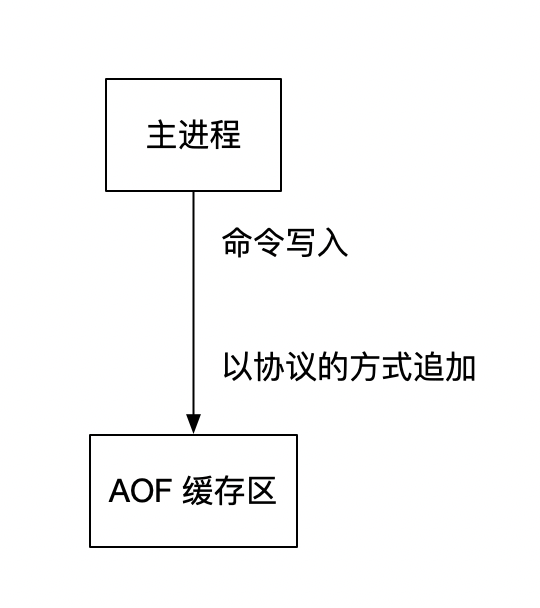
命令追加(append)
在执行写命令的时候,redis 不会马上把命令写入到文件,而是先把命令写入到 AOF缓冲区,然后再由缓冲区写入到文件。因为如果直接写入到文件的话,大量的 硬盘IO 可能会造成系统的不可用
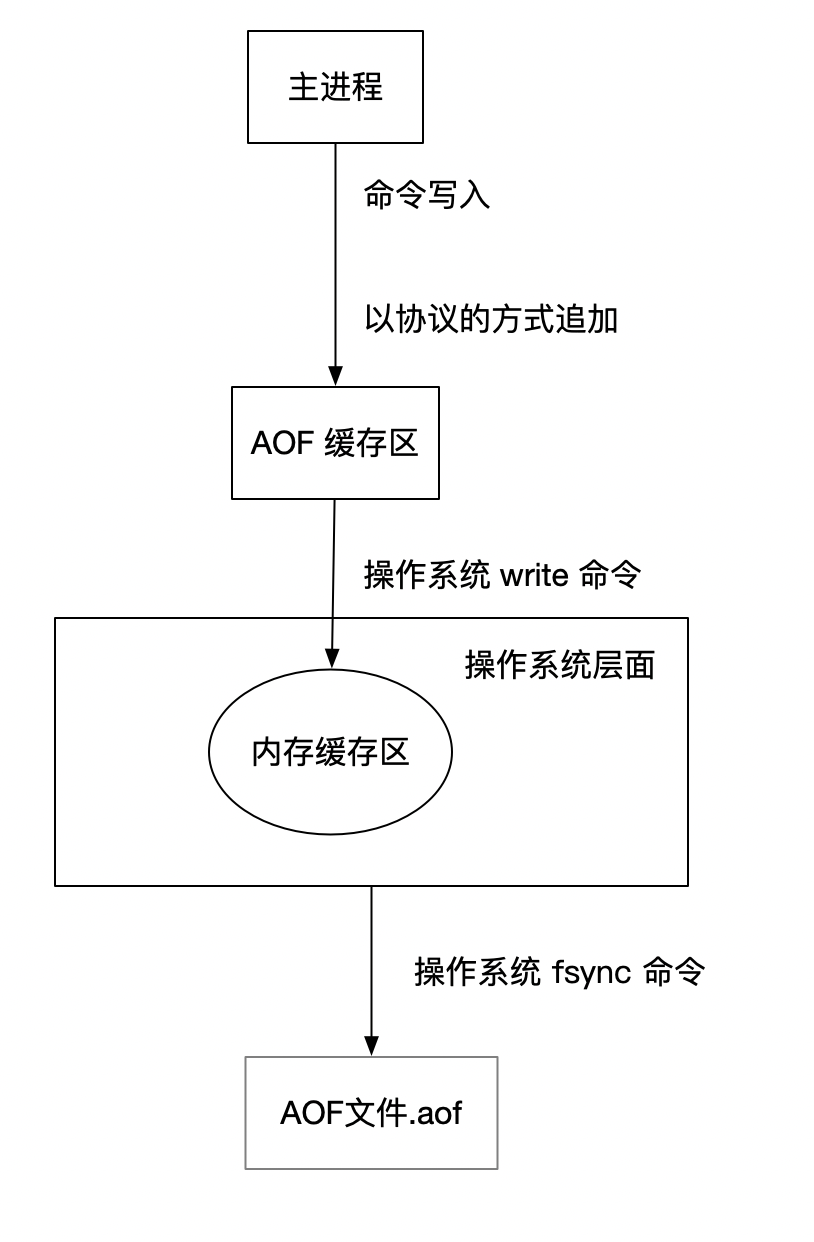
文件写入和文件同步
redis提供了多种机制来把缓冲区的数据写入到磁盘文件,这部分操作将由操作系统的 write 和 fsync 来完成。
write 命令: 当用户调用 write 函数将数据写入到文件的时候,数据会先存储在内存缓冲区里,等到填满内存缓冲区或超过了指定时间,才真正的把数据写入到磁盘的文件
fsync 命令:这句命令会立即将缓存区的数据写入到磁盘的文件
所以,基于以上说明, redis 提供了几种选项来让用户选择 AOF缓冲区的同步策略
redis 同步策略
redis 的同步策略由配置文件中的 appendfsync 参数来决定,有以下三种参数
- always: 每当数据写入到 AOF 缓冲区的时候,立马调用系统 fsync 函数,把缓冲区的数据同步到磁盘文件。这种方法会造成大量的磁盘 IO,影响 redis 甚至系统的正常使用。
- no: 命令写入到缓冲区后,redis层面就不管了了,然后交由操作系统来把数据写入到内存缓冲区,再每个周期(30s)同步一次内存的数据到磁盘文件,这种方式相当于每过 30s 把文件存储到磁盘文件(实际上时间会有偏差,但基本是这个意思)。这种情况下还是可能会造成 30s 内的数据丢失
- everysec: 命令写入 aof 缓冲区后,由线程来执行 write 函数,让他存储到内存缓冲区,然后,由另一个线程每隔一秒执行一次 fsync。
everysec 是前两种策略的折中方案,这种方式能很好的平衡数据的完备和系统的安全性,将数据丢失降低到 1s
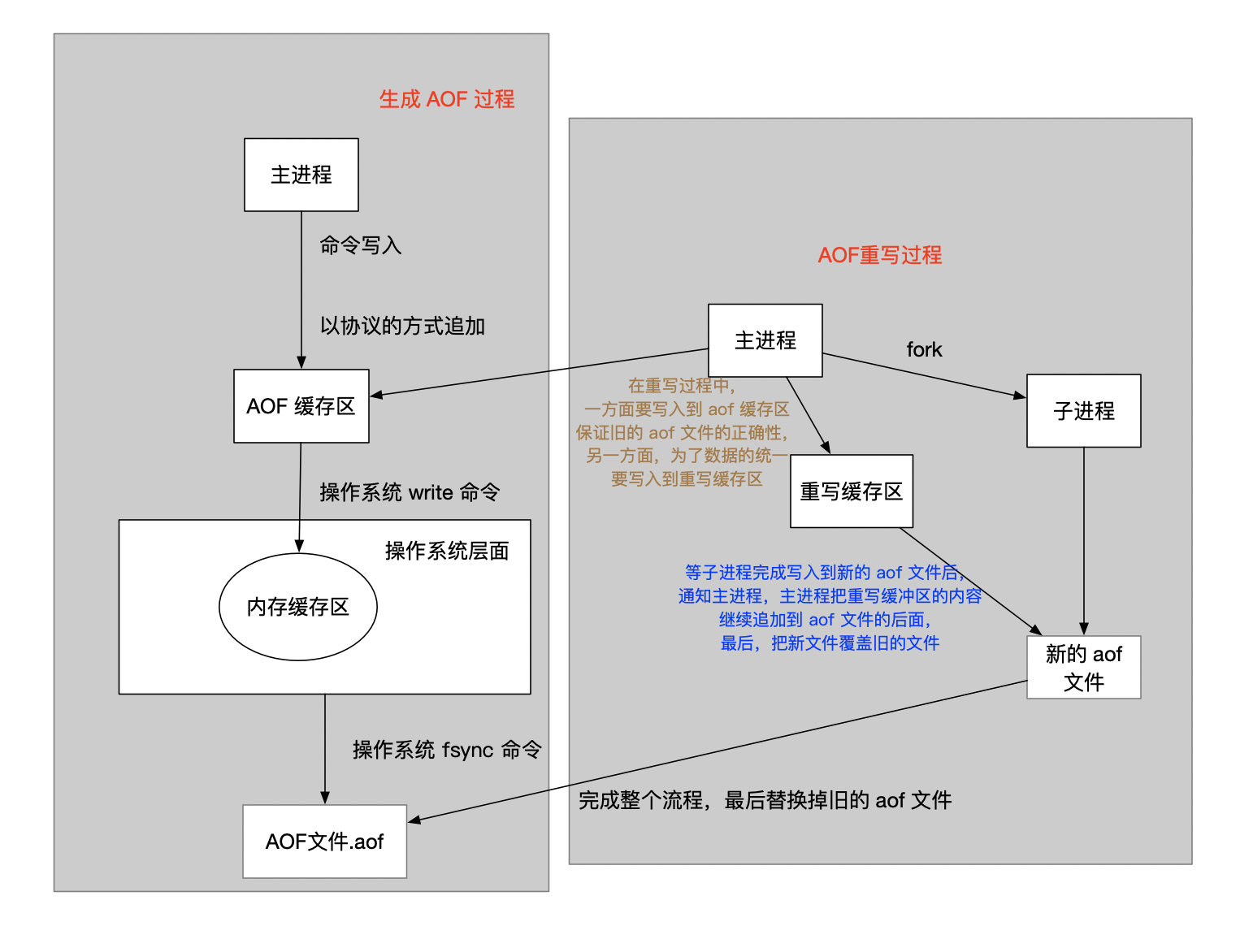
AOF重写机制
随着 AOF 的执行,文件的体积势必会越来越大,如果不加以控制,最终肯定会占满整个磁盘的空间。所以,也就有了 AOF 重写机制
需要说明的是,重写并不会对已有的 aof 文件进行操作!!!该过程仅仅只是把当前进程内的数据转换为写命令
为了说明这一点,举个简单的例子
1 | # 假设服务器对键list执行了以下命令 |
当前列表键list在数据库中的值就为[“A”, “B”, “C”, “D”, “E”]。要使用尽量少的命令来记录list键的状态,最简单的方式不是去读取和分析现有AOF文件的内容,而是直接读取list键在数据库中的当前值,然后用一条RPUSH list “A”, “B”, “C”, “D”, “E”代替前面的命令。
过程如下:
- 系统检测到目前符合重写的条件,则 fork 子进程来进行重写操作(因为如果由主线程来完成操作会造成操作阻塞)
- 由子进程来操作重写的过程中,中途服务器执行了写/删命令,这种情况下,如果不处理的话,会造成新的 aof 文件与现有数据内容不一致。
- 那么,就引入了新的缓存区,AOF重写缓存区,把这段时间内产生的操作都写入到这个缓存区,等到整个重写过程完成以后,再把这个缓冲区的内容写入到新的 aof 文件即可。
参考:
https://blog.csdn.net/hezhiqiang1314/article/details/69396887