functioncaculate() { var nums = ['one', 'two', 'three']; var i for (i = 0; i < nums.length; i++) { setTimeout(function() { console.log(i, nums[i]) }, 100) } }
caculate()
// 实际调用栈: 第 1 次循环: i = 0, 由于 setTimeout,挂起执行`console.log(i, nums[i]` 第 2 次循环: i = 1, 由于 setTimeout,挂起执行`console.log(i, nums[i]` 第 3 次循环: i = 2, 由于 setTimeout,挂起执行`console.log(i, nums[i]` // 执行完最后一次循环后,i++ ----> i = 3
functioncaculate() { var nums = ['one', 'two', 'three']; for (var i = 0; i < nums.length; i++) { let j = i // let 不会存在变量提升 setTimeout(function() { console.log(j, nums[j]) }, 100) } } caculate()
方案 2:消除对 i 的引用
1 2 3 4 5 6 7 8 9 10 11 12
functioncaculate() { var nums = ['one', 'two', 'three']; for (var i = 0; i < nums.length; i++) { // 匿名作用域,j 是 i 的复制,不是引用 (function(j) { setTimeout(function() { console.log(j, nums[j]) }, 100) })(i) } } caculate();
方案还有挺多,由于 es6 的基本都兼容主流浏览器了,一般都会写成方案 1
1 2 3 4 5
for (let i = 0; i < nums.length; i++) { setTimeout(function() { console.log(i, nums[i]) }, 100) }
var right = true if (right) { var count = 0; count ++; console.log(count); // 1 } console.log(count); // ?
对于 ? 处会打印什么?在我第一次看到这段代码的时候,我也会直觉性的认为他会打印 count is undefined,因为我认为 count 的包含在 if 的块作用域内的,然而事实是 ? 处的 count 也打印了 1,问题在于我忽略了变量提升这茬事了,稍后也会描述到,现在可以简单理解为在 if 块内用 var 声明的变量,最终也会等同于在 if 外层声明
let
基于上述的块作用域提到的示例代码片段,产生了与预期不一致的行为 – 预期是 count 仅在 if 块内可用,如何才能产生预期的情况?很简单,把 var 改为 let 即可。
let 是 es6 引入的新的关键字,提供了除 var 以外的另一种变量声明的方式,let 最有用的地方在于声明的变量仅在块内起作用。
再次执行上述代码,发现与预期情况一致了:count 仅在 if 作用域内生效
1 2 3 4 5 6 7
var right = true if (right) { let count = 0; count ++; console.log(count); // 1 } console.log(count); // Uncaught ReferenceError: count is not defined
除此以外 ,也可以 显示的定义块作用域,如下代码也能产生预期效果:
1 2 3 4 5 6 7 8 9
var right = true if (right) { { let count = 0; count ++; console.log(count); // 1 } console.log(count); // Uncaught ReferenceError: count is not defined }
所以当在20页范围之内,我们可以采取前端传送 id 数组给后端获取数据,此时后端的 sql select * from users where id IN (1..20),当超过 20 页,再通过后端分页获取数据 select * from users offset 201 limit 10
d. 借助 redis sortedset 结构
Mysql 不能很好地解决从一个很长的序列中取出任意一段数据的问题,而造成这一问题的根源在于这些数据是存放在磁盘上的,磁盘不适合做此类的随机读的操作。所以想,如果能有一个程序,管理一些很大很大的放在内存中排序数组就好了,因为对内存中的数组做下标访问,是非常快速的。做了一下调查正好发现,redis提供了此类的功能。
ZADD key score member [[score member] [score member] …]
将一个或多个 member 元素及其 score 值加入到有序集 key 当中。如果某个 member 已经是有序集的成员,那么更新这个 member 的 score 值,并通过重新插入这个 member 元素,来保证该 member 在正确的位置上
值得一提的是,在前端跨域的解决过程中,当采用 CORS 方法来解决跨域问题的话,非简单请求的CORS请求,会在正式通信之前,增加一次HTTP查询请求,称为”预检”请求(preflight),”预检”请求用的请求方法是OPTIONS,表示这个请求是用来询问的。头信息里面,关键字段是Origin,表示请求来自哪个源。
302 Found 表示临时重定向 Moved Temporarily。由于这样的重定向是临时的,客户端应继续向原有地址发送以后的请求,只有在 Cache-Control 或 Expires 中进行了指定的情况下,这个响应才是可缓存的。
303 See Other 作用和 302 基本一致,表示新的资源在其它URI,需要用 GET 方法请求它。 302 也能实现,但是当你希望客户端明确的使用 GET 请求进行访问另一个 URI 时应当使用 302 比较符合规范。
304 Not Modify 当客户端的请求头含有 IF-Modified-Since、If-None-Match、If-Range、If-Unmodified-Since 任一首部时,服务端可以返回 304,表示客户端当前请求的资源没有变化,可以使用客户端本地的缓存,所以此时服务端不会返回任何主体数据。
307 Temporary Redirect 临时重定向,该状态码和 302 有着同样的含义,只是因为在日常使用中,302 标准是禁止 Post 请求转换为 Get 请求,但是实际使用时大家都不遵守这个标准。所以,就有了 307,它硬性的规定 POST请求不能变为 Get 请求,但是每种浏览器都有可能出现不同的情况
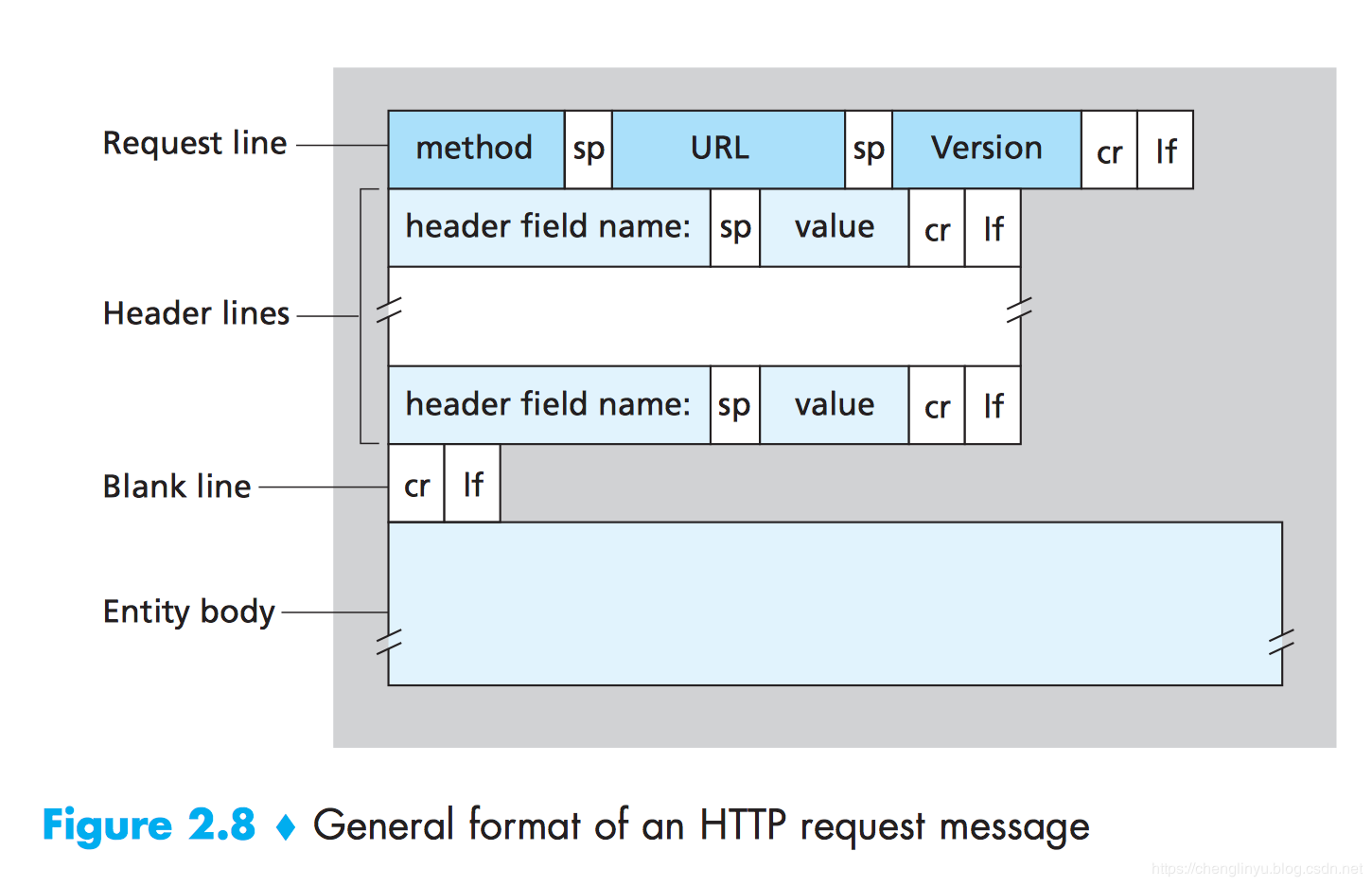
// 这是请求行 GET /index.html HTTP/1.1 // 以下是请求首部字段 Host: www.baidu.com Connection: close User-agent: Mozilla/5.0
GET 是没有请求主体的,POST 才有,平时我们提交的表单数据就是通过请求主体进行传输的
响应报文 报文首部分为:状态行、响应首部字段
1 2 3 4
HTTP/1.1 200 OK Content-Length: 662 Content-Type: text/plain; charset=UTF-8 Date: Wed, 19 Feb 2020 14:49:41 GMT
响应主体就是服务端传输回来的文本数据
HTTP1.0 vs 1.1 vs 2.0
1.0
1.1
2.0
长连接
需要使用keep-alive 参数来告知服务端建立一个长连接
默认支持
默认支持
HOST域
X
✔
✔
多路复用
X
-
✔
数据压缩
X
X
使用HAPCK算法对header数据进行压缩,使数据体积变小,传输更快
服务器推送
X
X
✔
长连接
http1.1默认保持长连接,数据传输完成保持tcp连接不断开,继续用这个通道传输数据
管道化
基于长连接的基础,我们先看没有管道化请求响应:
tcp没有断开,用的同一个通道
1
请求1 > 响应1 --> 请求2 > 响应2 --> 请求3 > 响应3
管道化的请求响应:
1
请求1 --> 请求2 --> 请求3 > 响应1 --> 响应2 --> 响应3
即使服务器先准备好响应2,也是按照请求顺序先返回响应1
虽然管道化,可以一次发送多个请求,但是响应仍是顺序返回,仍然无法解决队头阻塞的问题
题外话:为什么管线化必须按照顺序进行返回呢? 由于 HTTP/1.1 是个文本协议,同时返回的内容也并不能区分对应于哪个发送的请求,所以顺序必须维持一致。比如你向服务器发送了两个请求 GET /query?q=A 和 GET /query?q=B,服务器返回了两个结果,浏览器是没有办法根据响应结果来判断响应对应于哪一个请求的。
首先我们来了解一下 XML 的封解包过程。XML 需要从文件中读取出字符串,再转换为 XML 文档对象结构模型。之后,再从 XML 文档对象结构模型中读取指定节点的字符串,最后再将这个字符串转换成指定类型的变量。这个过程非常复杂,其中将 XML 文件转换为文档对象结构模型的过程通常需要完成词法文法分析等大量消耗 CPU 的复杂计算。
反观 Protobuf,它只需要简单地将一个二进制序列,按照指定的格式读取到 C++ 对应的结构类型中就可以了。
所以结论当然是:容量小,速度快,跨平台
缺点
通用性来说的话,如果面向开放的 api 的话,还是 JSON 比较通用,为什么呢?一方面是因为大家都熟悉这套玩法了,另一方面就是省事,不用每次都编译 proto 文件